01
Scalable scraping
Distributed crawl clusters with adaptive concurrency, retry logic, and smart scheduling to keep throughput high without sacrificing stability.
Future-ready data extraction
OVERFLOW LABS LTD builds high-throughput extraction systems, resilient scrapers, and compliance‑minded automation tailored to your stack. Move from raw HTML to structured, auditable datasets with precision and speed.
99.9% uptime workflows
Resilient retry & proxy orchestration
Structured outputs
JSON, Parquet, and event streams
Compliance‑minded
Policy-first monitoring & audits
Live pipeline view
Extraction orchestration
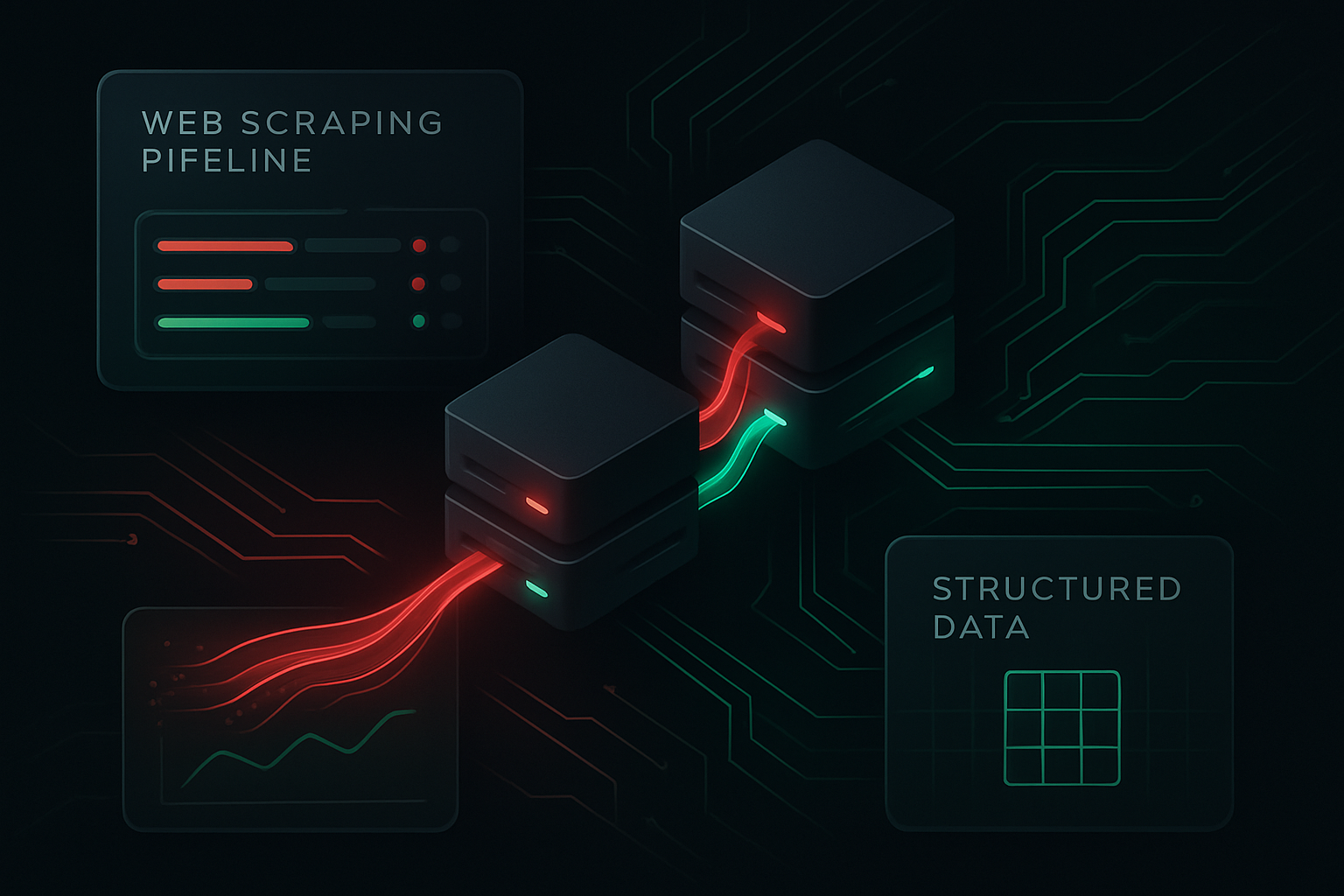
Core Capabilities
Overflow Labs delivers compliant, resilient data extraction with performance tuning, robust proxy management, and structured delivery pipelines designed for production workloads.
Distributed crawl clusters with adaptive concurrency, retry logic, and smart scheduling to keep throughput high without sacrificing stability.
Normalized datasets with schema validation, deduping, and automated exports to databases, cloud storage, or your analytics stack.
API-first outputs, webhook triggers, and bespoke connectors for CRMs, BI tools, data warehouses, or internal pipelines.
Adaptive parsers, DOM diffing, and self-healing extraction logic that stays reliable as sites evolve.
Rotating proxy pools, fingerprint control, rate governance, and compliance-aware crawling to keep access stable.
Clean JSON, CSV, and Parquet with versioned schemas, sample datasets, and full documentation for fast onboarding.
We design and operate custom data pipelines that align with your compliance and performance targets.
OVERFLOW LABS LTD is a modern programming company delivering secure, compliant, and high-performance data extraction tooling. We partner with technical teams to engineer resilient crawlers, structured data pipelines, and automated workflows that stay maintainable as your requirements evolve.
Purpose-built scrapers, headless automation, and API layers designed around your domain logic and data contracts.
Monitoring, retry strategies, and compliance-minded engineering that protect uptime and data integrity.
Batch orchestration, queue-driven workloads, and scalable infrastructure tuned for high-volume extraction.
Clean, normalized datasets that power analytics, pricing intelligence, research, and decision automation.
System Snapshot
Scraping Control Plane
99.98% job success rate
Automated recovery keeps extraction consistent.
Compliance-aware routing
Adaptive throttling and policy-driven access controls.
Structured data delivery
Normalized outputs for analytics and product ingestion.
Operational Proof Points
OVERFLOW LABS LTD engineers data pipelines built for performance, resilience, and governance. These signals show how we prioritize accuracy, integration speed, and automation efficiency.
Deployment
Days, not quarters
Modular extraction stacks accelerate onboarding and reduce time-to-data. Our teams ship production-ready scraping suites in short, predictable cycles.
Integration Surface
Flexible APIs
REST, event streams, and warehouse-ready exports.
Reliability Focus
Accuracy first
Continuous validation and structured QA checkpoints.
Automation impact
Major efficiency gains
Workflow automation eliminates manual extraction steps, enabling operations teams to scale data capture with minimal overhead.
Compliance minded
Governed pipelines
Built-in rate controls, audit trails, and configurable retention policies keep data programs transparent and sustainable.
FAQ
OVERFLOW LABS LTD builds dependable scraping systems with compliance-minded engineering, robust anti-block strategies, and structured data pipelines. Here are the most common questions we receive from teams evaluating our tools.
Yes. We design tailored scrapers for complex targets, authentication flows, and highly structured data requirements. We align on throughput, latency, and compliance constraints before shipping production-ready pipelines.
We output clean, normalized datasets in JSON, CSV, Parquet, or direct warehouse/BI destinations. Schemas are versioned and documented so downstream systems can trust every field.
Our stack blends adaptive rotation, fingerprint hardening, rate-aware scheduling, and health monitoring. We model target behavior to keep capture consistent while staying within policy and legal constraints.
We support startups and enterprise teams that need reliable, compliant data collection at scale. Typical users include operations, pricing, research, and engineering teams with critical data dependencies.
Scraping stacks require active upkeep. We monitor site changes, alert on extraction drift, and deliver scheduled health reports so your pipelines stay trusted and current.
We handle selector updates, schema changes, proxy tuning, and performance checks with SLAs matched to your data criticality.
Absolutely. We deliver data via secure APIs, S3, webhooks, or direct warehouse loads, aligned with your DevOps and security requirements.
Compliance-minded
Our engineering team prioritizes respectful access, rate limiting, and clear legal boundaries while delivering performance at scale.
Schedule a technical consult